Project: PSP Dataviewer
Test data accessibility for faster iterative dev :)
Table Of Contents:
You can't get good hardware test results without good data. You really can't get good results if you can't access that data.
TLDR;
I created a backend, an API, and some web interfaces to store, process, and make rocket test data quickly and affordably accessible to anoyone with a web browser.
The Issue
Making test data accessible to everyone on a team is much harder than it should be. Existing tools are too expensive, too complicated, or just don't fit a collegiate rocketry team's needs.
Even just distributing the data has its own issues: we could distribute the raw data files (.tdms, parquet/influxDB, .csv, etc) via Google Drive or S3 and have each user manually plot the data they want to see, but then we'd have to store the data files and the test metadata that goes along with those files (synced timestamp offsets, raw data conversion slopes and offsets, annotations, etc). Heck, we could even pre-process all of the data and store it somewhere accessible - but then we'd be limiting accessibility to those who know how to parse and plot the data.
Solution
I built four systems:
- A frontend "plotting" webapp
- An admin webapp
- An API for accessing data
- A backend to manage all three of the above systems
The vast majourity of people will interact with the webapp:
Architecture
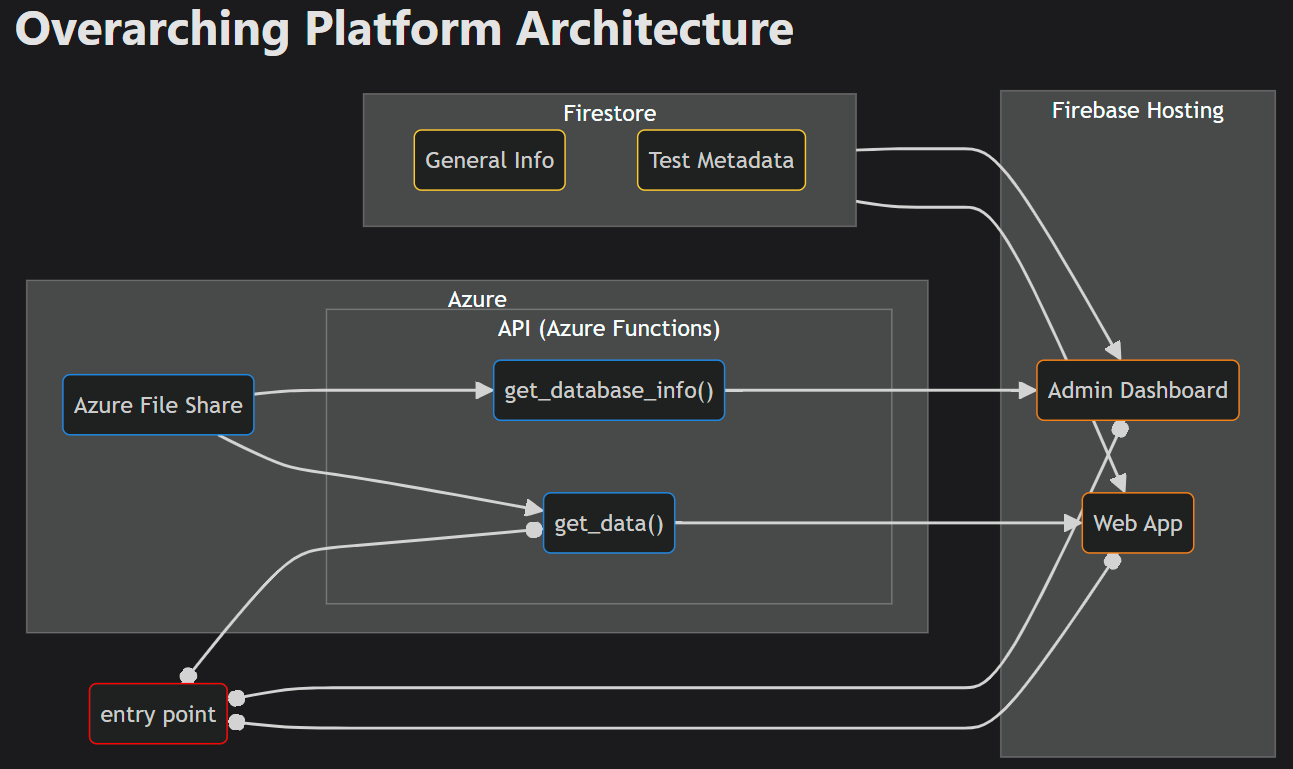
I have some mermaid diagrams on the documentation that do a pretty good job explaining how everything gets orchestrated together, but I'll run through some design decisions and previous implementations here.
To re-iterate, the goal of this project is to make high-frequency timeseries data quickly and affordably accessible - so all design decisions are based on the following questions:
- Is it cheap (total stack cost of <$5 per month)?
- Is it fast (warm response time of <2s for four random datasets over a random time period)?
- Is it accessible (no user accounts required to read & can support our data load)?
A note on the expected data load: Tests are conducted relatively infrequently (at best ~once per week). Once tests are conducted, there's a huge demand for data review capabilities shortly following that test - and then almost no load until the next test occurs. This means I need an architecture that can handle infrequent (but still fast) data ingest, can baseline $0/month in processing/retrieval costs, and can instantly scale to support low-frequency, short-duration, "burst" load profiles.
Data Storage
Chosen technology: HDF5 data files stored in an Azure File Share
I did a ton (read: nearly two months) of dev work to get AWS Timestream to work, but ultimately called it quits because:
- It required authentication to make requests
- Authentication with Cognito and getting the right permissions for an anonymous user was an enourmous pain and didn't end up working
- Downsampling data would be an added "compute" cost that would at least 5x the estimated $3/month cost I had calculated based on expected usage patterns
- Response times were averaging ~5s without compute, ~7s with cheap compute
- Ingesting data was also clunky and required a bunch of workarounds to get unsynced and null data to be handled correctly
- AWS's UX was clunky and kinda annoying
Hosted InfluxDB was simply too limiting and too expensive. With each test averaging ~5GB in raw compiled file size (.csv), the ingest rate of 300MB/5 mins wouldn't cut it. Even worse was the query rate: 3000MB/5 mins wouldn't hold up when we were hosting a data review with an entire team.
TimescaleDB was also just too expensive to put serious dev work into. I played around with it a bit, and even developed the front-end plotting capabilites with it in mind, but it quickly got superceded.
Other timeseries DB options like Redis, Graphite, and KDB+ required a hosted deployment that would (again) quickly balloon past my price range.
After trying out HDF5 - and discovering its built-in compression - I was sold. To figure out where to actually store the data though, I'd have to turn to which service would let me quickly access the data. Once I figured out that solution (Azure, see next section), I decided on an Azure File Share to keep things accessible.
Data Access (API)
Chosen technology: Azure Functions (Python) with a mounted volume (Azure File Share) under the "Flex Consumption" pricing plan.
There were really only four options:
- Firebase Functions
- Didn't allow me to mount a volume to a function instance, and downloading an HDF5 file from a storage bucket was too slow
- AWS Lambda/S3
- Lambda Layers had a size limit that wouldn't work for storing more than a few tests worth of data
- S3 access was also way too slow
- Google Cloud Run Functions
- At the time, couldn't mount a volume to a function (although I hear you can now?)
- Fetching from a storage bucket was too slow
- Azure Functions/Azure File Share
- Could easily and programmaticaly mount a volume to a functions instance
- A UI that would mop the floor with AWS
- Has a tiered-storage pricing plan AND a pay-as-you-go functions pricing plan that also lets me set a minimum warm instance count (!!!)
After choosing Azure, I also chose to write the functions in Python - I'd prefer to write something like this in Rust, but Azure only has functions runtimes for .NET, Java, Python and JS. Python isn't the fastest runtime to use in this case, but it's the one I was most comfortable with.
With a warm stack, total retrieval time averages ~1.5s to open and parse four datasets from the HDF5 file. Adding about a dozen milliseconds for downsampling and json packaging and...tada!
Backend & Service Orchestration
Test metadata and annotations are all written to and stored in a Firestore database. I also wrote a number of Firebase Functions (Python, again bc it was just easier) to help manage and keep this database and the API data in-sync.
To keep the API in-sync with the firestore database, all API data is created on the firebase side of the system (just going to call this the backend). A bunch of raw data files (TDMS and CSV files) are uploaded to a backend bucket, and then a document is written to the database - which automatically kicks off a process to create an HDF5 file (using a Python package I developed) and write it to the backend storage bucket.
Once there's an HDF5 file on the backend, another document is written to the backend, which triggers a firebase function to transfer the file to Azure. Once the file transfer is complete, a final document is written with all test metadata so that it can be identified by the webapps.
To manage Azure "warm" instances, I wrote a couple firebase functions - both of which interface with the Azure CLI to query and make changes to the API config. There's one backend function that queries Azure for the number of warm instances, and another that sets a minimum warm instance count for the API. Since Azure can scale up without calling these functions, the only purpose of these functions is to prep the API for a substantial change in demand (i.e: we're about to do a data review, or we just finished a data review). This method of manually scaling baseline "warm" instances reduces cost dramatically - and is a feature unique to Azure's functions service.
Main & Admin Webapp
The original webapp was actually hand-written in Typescript by yours truly - meaning it didn't use any framework at all. I manually updated each element using JS document calls whenever I wanted something to change. In fact, the original webapp had more features (as of writing) than the current version does (I'm haven't translated the calc channel engine to work in v2 yet).
The webapps (v2) are written in Typescript and built using Solid.js. After dealing with the pain of managing state at a global level and with no re-useable components in the original version, I wanted to move to a super lightweight componet-based solution.
- React was too heavy for my liking. You can definetly make some fast apps with react, but dealing with the virtual DOM and not having a fully reactive system out-of-the-box sealed the deal against React for me.
- Webcomponents/Lit seemed like a good solution, especially because they were a standard, but using normal webcomponents meant interfacing with a low-level JS API that just felt like too much developer overhead. Lit also wasn't ideal because using decorators for every propoerty or element I want to create looked way too complex for someone to quickly pick up and understand. Plus, it's harder to distinguish which reactive propoerties are being updated in a Lit component
Tools
Obviously you want to view data quickly and afforadbly, but wouldn't it also be helpful to provide a suite of tools to analyze and present that data much faster?
Sharelinks
Sometimes you're looking at some data and you want to share exactly what you're looking at with someone else - but not with a screenshot. If you want another person to analyze that section of data - or you want to reference or cite some specific data in a report or slideshow, screenshots just don't cut it.
So, I created a way to share the existing state of the app just by clicking "Share" in the top right corner. By clicking that link, you copy a unique url to your clipboard - so that you can share exactly what you're looking at with anyone else who has access to the internet.
Plot Export
Made some super-simple export buttons, allowing both image and data export:
- PNG Image Export:
- Copy to clipboard
- Download as PNG
- Data export
- Plot window CSV download
- Full resolution CSV download
Measuring
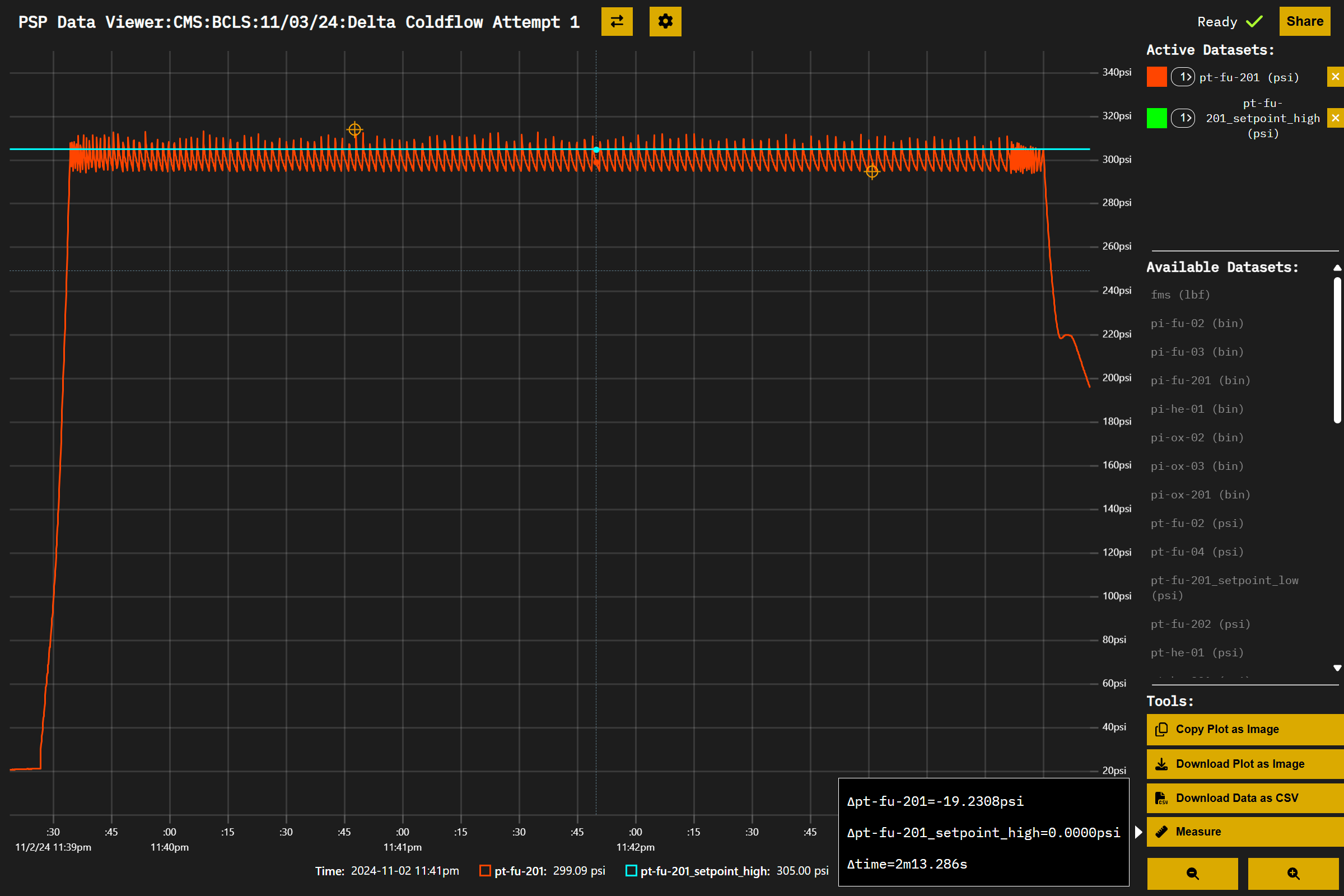
To quickly measure the differnece between two points on a plot, I created a "measure" tool.
Using keyboard hotkeys (the keys "1" and "2"), a user can place measuring points on the plot and get a full list of differences between all visible datasets between those plots.
Example:
Calcs Engine
I wrote a "calcs engine" to apply formulas to datasets for better analysis. I also wrote it to allow combining different datasets within a single formula - and extended it by allowing a "time window" of data for each dataset being worked with to be available for analysis.
Documentation
View actual docs